If you have ever been curious about the contents of a YouTube video but did not feel like sitting down and watching the whole thing, you may have wished that you could simply ask someone who has watched it about its contents. How about an AI model that you can provide the YouTube video link to, it will then watch the video for you and answer any questions you have about it?
This is a fun cloud project that incorporates a simple app front-end to submit a YouTube URL and a question, some back-end logic to download and transcribe a YouTube video, an artificial intelligence component to provide a query engine to query the video contents and a containerised large language model to send the query to.
High-Level Architecture Diagram
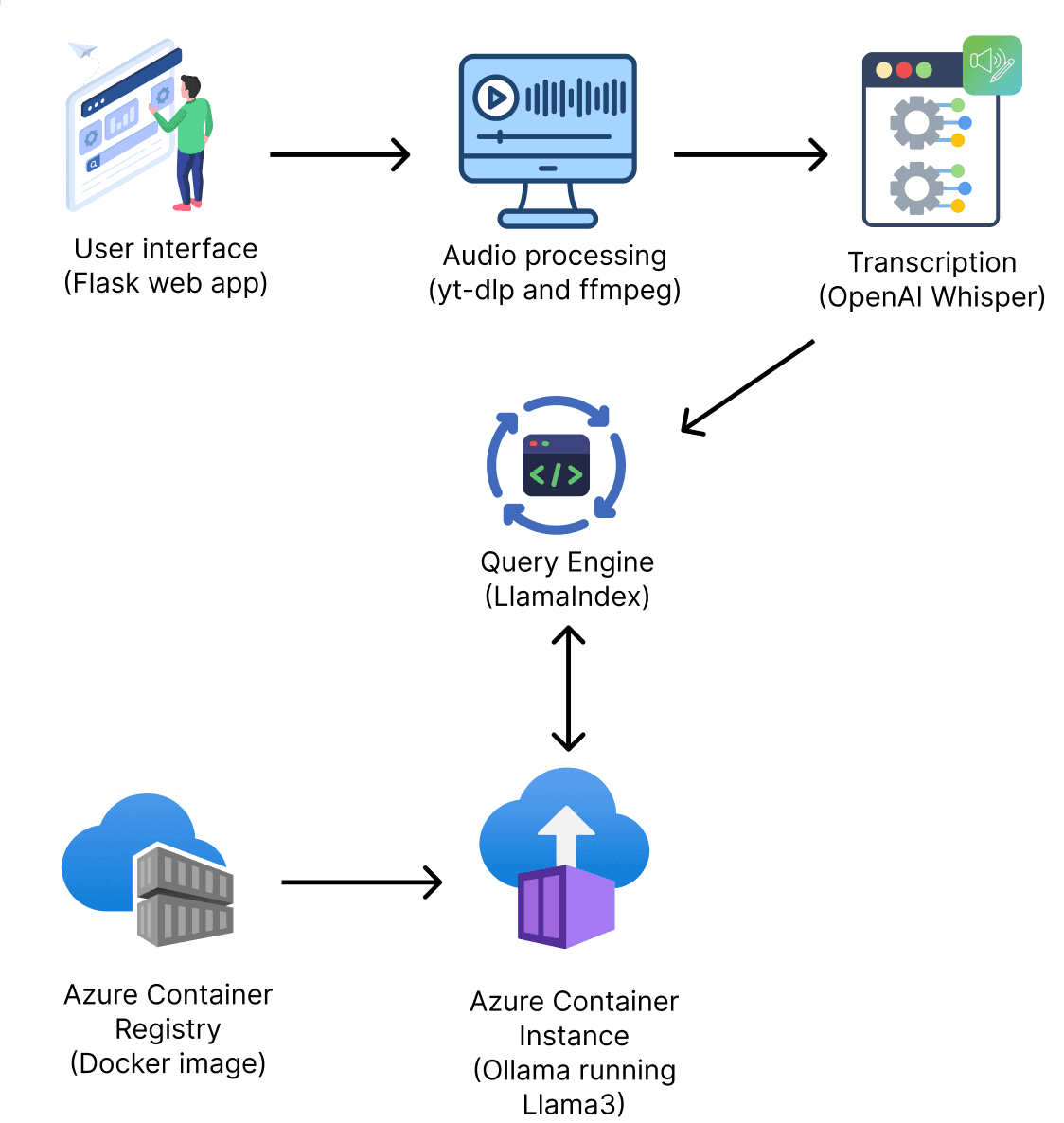
User interaction: User submits a YouTube URL and a question about the video via the web interface.
Video Processing: Audio is extracted using yt-dlp to download audio and ffmpeg to process it.
Transcription: OpenAI Whisper processes the audio and returns the transcription.
Query Engine: LlamaIndex processes the transcription and user question, forwarding them to the large language model hosted in an Azure Container Instance
Azure Container Instance: The Llama3 large language model analyses the input from LlamaIndex and generates a response which is displayed to the user.
Key Features
Downloads and extracts audio from YouTube videos.
Transcribes audio to text using OpenAI Whisper.
Allows users to query the transcription with an LLM (Llama3 model) for summaries or other information.
Runs as a web application with Flask for user interaction.
Deployment
Local Development
Requirements:
Python 3.11
Docker
ffmpeg
PowerShell with AZ CLI module
Install-Module -Name Az -AllowClobber -Force
Dependencies
Python libraries: Flask, yt-dlp, whisper, ffmpeg, LlamaIndex
Docker: Hosts Ollama container running Llama3
pip install flask
pip install yt-dlp
pip install openai-whisper
pip install llama-index-core
pip install llama-index-readers-file
pip install llama-index-llms-ollama
pip install llama-index-embeddings-huggingface
Cloud Deployment
We can begin by getting our Large Language Model (LLM) up and running in a container running Ollama. Ollama is a platform for deploying and running large language models (LLMs) locally or in containerized environments. Here we will use Ollama to create a running instance of Llama3 that we can query directly or send queries to via our web app.
Docker Setup
1. Pull Docker Image - Downloads the Docker image for `ollama/ollama` from Docker Hub.
docker pull ollama/ollama
2. Run Docker Container - Creates and starts a container named `ollama` exposing port `11411`.
docker run --name ollama -d -p 11411:11411 ollama/ollama
3. Execute Commands in Running Docker Container - Runs the `llama3` model within the container.
docker exec -it ollama ollama run llama3
4. Commit Changes to Docker Image - Saves the container's state to a new image tagged `ollama/ollama-llama3`.
docker commit ollama ollama/ollama-llama3
2. Azure Container Setup
Create an Azure Container Registry (ACR) to host our custom Docker image.
Push the Llama3 image to the ACR.
Login to Azure CLI
Create a resource group and an Azure Container Registry
az group create --name YT_RAG_APP-RG --location eastus
az acr create --resource-group YT_RAG_APP-RG --name ytragregistry --sku Basic
Login to the Azure Container Registry
az acr login --name ytragregistry
Tag Docker Image - Tags the local Docker image with the Azure Container Registry URL
docker tag ollama/ollama-llama3 ytragregistry.azurecr.io/ollama-llama3:latest
Push Docker Image to Azure Container Registry
docker push ytragregistry.azurecr.io/ollama-llama3:latest
Create an Azure Container Instance - Deploys a container instance in Azure with the specified configuration.
az container create `
--resource-group YT_RAG_APP-RG `
--name ollamacontainer `
--image ytragregistry.azurecr.io/ollama-llama3:latest `
--cpu 4 --memory 16 `
--ports 11434 `
--dns-name-label ollama-container `
--location eastus `
--environment-variables OLLAMA_PORT=11434
3. Flask Application
Flask is a lightweight web framework for Python that is used to build web apps. We need to run this Flask app in Python 3.11 due to some dependencies not being compatible with more recent versions of Python.
The Flask application serves as the backend of the project while also delivering the HTML files that form the front-end interface of the app, enabling users to interact with the system through a web browser.
I have made the app as simple as possible as it's purpose is to provide a chance for some experimenting with cloud services, rather than to serve as a robust web application on its own. Therefore you will notice it's pretty basic but serves as a functional app that gets us experimenting.
import os
import subprocess
import uuid
from flask import Flask, request, render_template
import yt_dlp
import whisper
# LlamaIndex / Ollama imports
from llama_index.core import VectorStoreIndex, Document, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
app = Flask(__name__)
############################
# Configure LlamaIndex #
############################
# Adjust the endpoint to reflect the address of your Docker container.
# If you are running the container locally as a test, by default Ollama's REST API is on port 11411.
# If Docker is on the same machine, 'localhost' should be fine.
# If running in the Azure Container Instance, remove localhost and add the IP address of the container.
OLLAMA_ENDPOINT = "http://localhost:11434"
# Set up embeddings and LLM once (shared config)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
Settings.llm = Ollama(model="llama3", base_url=OLLAMA_ENDPOINT, request_timeout=360.0)
@app.route("/", methods=["GET", "POST"])
def index():
transcription = None
summary = None
if request.method == "POST":
youtube_url = request.form.get("url", "").strip()
if youtube_url:
# 1. Generate unique filenames for temp files
unique_id = str(uuid.uuid4())
video_filename = f"video_{unique_id}.mp4"
audio_filename = f"audio_{unique_id}.wav"
# 2. Download the audio from YouTube using yt_dlp
ydl_opts = {
'outtmpl': video_filename,
'format': 'bestaudio/best',
'quiet': True,
'cookiesfrombrowser': ('firefox',)
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([youtube_url])
except Exception as e:
transcription = f"Error downloading video: {e}"
return render_template("index.html", transcription=transcription)
# 3. Extract audio using ffmpeg
cmd = [
"ffmpeg", "-y",
"-i", video_filename,
"-ar", "16000",
"-ac", "1",
audio_filename
]
try:
subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
except subprocess.CalledProcessError as e:
transcription = f"Error extracting audio: {e}"
if os.path.exists(video_filename):
os.remove(video_filename)
return render_template("index.html", transcription=transcription)
# 4. Transcribe audio using Whisper
try:
whisper_model = whisper.load_model("base") # or 'small', 'large', etc.
result = whisper_model.transcribe(audio_filename)
transcription = result["text"].strip()
except Exception as e:
transcription = f"Error transcribing audio: {e}"
# Clean up temporary files
if os.path.exists(video_filename):
os.remove(video_filename)
if os.path.exists(audio_filename):
os.remove(audio_filename)
# 5. Build an in-memory LlamaIndex with the transcription
if transcription and not transcription.startswith("Error"):
try:
doc = Document(text=transcription)
index = VectorStoreIndex.from_documents([doc])
query_engine = index.as_query_engine()
# 6. Hard-coded query to summarize the main subject of the transcript
user_query = "Summarize the main subject of the video"
response = query_engine.query(user_query)
summary = str(response)
except Exception as e:
summary = f"Error with RAG query: {e}"
return render_template("index.html", transcription=transcription, summary=summary)
if __name__ == "__main__":
app.run(debug=True)
The HTML for the web app's front end is provided below and should be placed in a templates folder within the directory where the Flask application is located.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width">
<title>Video Transcription and Summarization</title>
</head>
<body>
<h1>Video Transcription and Summarization</h1>
<form method="POST" action="/" style="margin-bottom:20px;">
<label for="url">YouTube URL:</label><br>
<input type="text" id="url" name="url" style="width:300px;" required><br><br>
<label for="question">Your Question:</label>
<input type="text" id="question" name="question"><br><br>
<button type="submit">Submit</button>
</form>
<h2>Transcription:</h2>
<p>{{ transcription }}</p>
<h2>Summary/Answer:</h2>
<p>{{ summary }}</p>
</body>
</html>
4. Running the app
Once the container instance is running in Azure and Flask app is running locally (or in the cloud too if you wish) you can start using the app by browsing to the webpage http://localhost:5000 and entering the URL of a YouTube video plus your question. After some loading, you'll get your answer!

